Agent 开发学习记录:LangGraph Local Server
之前已经能用 uv run python main.py 跑通一个最小 tool-calling agent。那一步解决的是"Agent 逻辑能不能在本地跑起来"的问题。
今天继续往前走一步:把这个 agent 写成一个本地服务。这样它就不只是 main.py 里的一个 Python 对象,而是可以被外部工具或外部程序通过 API 调用的服务。
这次主要验证两种调用和调试方式:
- 第一种是启动 LangGraph Local Server,然后用 LangSmith Studio 连接本地服务,在界面里输入问题、观察 agent 运行和工具调用过程。
- 第二种是用
langgraph-sdk写一个 Python 脚本,像真实客户端一样调用本地服务里的agent,确认 SDK 到 Server 再到 graph 的链路能跑通。
原来的运行方式很直接。main.py 里定义工具、定义 StateGraph、编译出 agent,最后直接调用:
这种方式适合刚开始理解 LangGraph。输入就在代码里,运行脚本就能看到结果。但它有一个限制:这个 graph 还只是一个 Python 文件里的对象,外部应用不能直接调用它。
所以今天真正要解决的问题是:怎么把 main.py 里的 agent 暴露给 LangGraph Server。
先把 graph 暴露出来
LangGraph Server 启动时关注的是文件里暴露出来的 graph 对象,不是 main.py 末尾那段测试调用。所以 main.py 里最关键的是这个顶层变量:
这里不需要像 JavaScript 一样写 export。Python 文件本身就是模块,只要变量定义在模块顶层,别的代码导入这个模块后就能访问它。
比如 LangGraph CLI 读取配置后,可以理解成做了类似这样的事情:
因此需要用 langgraph.json 告诉 CLI:从哪个文件里读取哪个变量。
当前配置是:
这里的 "agent": "./main.py:agent",冒号左边是 Server 对外暴露的 graph 名字,后面在 Studio、SDK 或 API 里调用时用的就是它。冒号右边是加载位置,从当前目录的 main.py 文件里读 agent 这个变量。
关于 if __name__ == "__main__" 的一个小插曲
接入 Server 的时候,我一开始问 AI:main.py 里原来的测试调用应该怎么改比较合适。AI 给的建议是把测试调用放进:
这个建议本身是合理的,但它的出发点是"尽量兼容现有功能":同一个 main.py 既能继续被直接运行,也能被 LangGraph Server 导入。
如果还想保留第一种方式,那么测试代码就应该放进 if __name__ == "__main__" 里。这样直接运行脚本时会执行测试调用,Server 导入文件时只会加载 agent,不会顺手执行测试输入。
但回到当前这个学习场景,其实已经不太需要再通过 uv run python main.py 来直接调用 agent 了。现在的重点是把 agent 暴露成服务,然后通过 Studio 或 SDK 从外部调用。所以从项目整理的角度看,也可以直接把 main.py 末尾那段脚本测试代码删掉,只保留 graph 定义和顶层的:
也就是说,if __name__ == "__main__" 不是这次接入 Server 的必需步骤。它更像是 AI 为了兼容"还能直接运行脚本"这个旧用法给出的保守改法。
不过这个过程刚好让我补了一下 Python 里的 __name__ 用法。
__name__ 是 Python 给每个模块自动设置的内置变量,表示当前文件是以什么身份运行的。
如果直接运行:
那么 main.py 里的 __name__ 会是:
如果是 LangGraph Server 根据 ./main.py:agent 导入这个文件,__name__ 通常会是模块名:
所以如果确实想让一个文件同时支持"直接运行"和"被别的地方导入",可以这样写:
但如果文件以后只作为 LangGraph Server 的 graph 模块使用,那就不需要保留这段脚本入口。测试和调试可以放到单独的脚本里。
安装 CLI 时的 [inmem]
为了启动本地 LangGraph Server,需要安装:
这里的中括号属于 Python packaging 里的 extra 语法:
意思是安装主包时,顺便安装它声明的一组可选依赖。langgraph-cli 是主包,[inmem] 是它额外提供的一组依赖集合,用来支持本地 in-memory dev server。
类似 npm 里有些功能需要额外装 plugin 的感觉:
Python 的 extra 更像是把"某个功能需要的一组额外依赖"提前命名好。使用者不用记住具体要补哪些包,只要写:
就会安装 langgraph-cli 本体,以及 inmem 这个功能所需的额外依赖。
如果只是运行:
其实不需要 langgraph-cli[inmem]。只有要用 LangGraph Server、Studio 或外部 API 调用 graph 时才需要它。
顺带提一下 dependencies: ["."],意思是当前目录就是项目根目录。Server 会拿这里的 pyproject.toml 准备运行环境。因为依赖都在根目录的 pyproject.toml 里,所以写 ["."] 就够了。
第一次启动遇到路径错误
一开始配置写成了:
启动时报错:
这个错误的原因是:main.py:agent 没有写成文件路径,CLI 把 main.py 当成了 Python 模块路径来解析。Python 会把它理解成 main 包下面的 py 子模块,所以才会说 'main' is not a package。
修复方式是加上当前目录前缀:
加上 ./ 后,它就明确表示一个文件路径。
Server 接管后,输入从哪里来
启动成功后,输入就不再写在 main.py 里了。
原来的脚本调用是:
Server 模式下,输入从外部传进来,形式类似:
可以从三个地方输入:
- LangGraph Studio
langgraph-sdkhttp://127.0.0.1:2024的 HTTP API
这一步的区别就是:之前 main.py 主动调用 agent.invoke(...),现在只暴露 agent,由外部客户端传入 input。
用 Python SDK 调一下本地 Server
除了在 LangSmith Studio 里点界面调试,也可以用 Python SDK 写一个很小的客户端脚本来调本地 Server。
当前的 test_agent.py 是这样写的:
这里的调用方式和直接运行 main.py 不一样。它不是在当前 Python 进程里直接执行 agent.invoke(...),而是先连到本地服务:
然后通过 Server 暴露出来的名字调用 graph:
这里的 "agent" 对应的还是 langgraph.json 里的配置:
所以这段脚本验证的是完整的外部调用链路:
运行时需要先启动本地服务:
然后另开一个终端执行:
这次输入的是:
输出里能看到模型先决定调用工具:
工具返回:
然后模型再根据工具结果生成最终回答:
所以 test_agent.py 更像是一个手动 smoke test。它不是为了测某个 Python 函数的内部逻辑,而是用来确认 SDK、Local Server、langgraph.json 和 main.py:agent 这整条链路都能跑通。
在 Studio 里观察工具调用
接着用 Studio 跑了一个算术问题:
Studio 左侧是 graph 结构,右侧是运行轨迹。
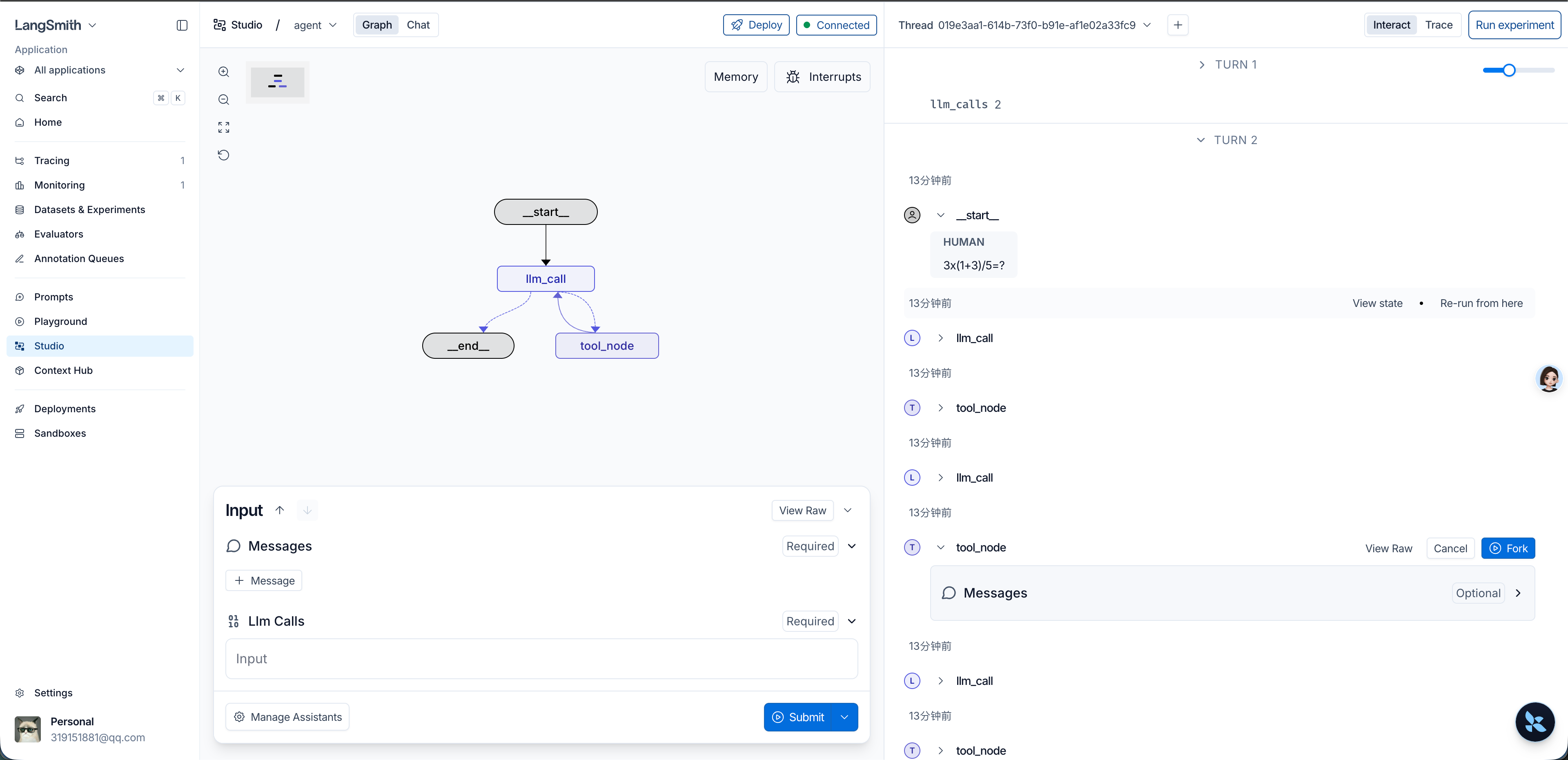
这个 graph 的结构很简单:
llm_call 负责调用带工具能力的模型,tool_node 负责执行工具。因为当前代码只注册了三个工具:
所以这个算式会被拆成几步:
从执行轨迹看,它会在模型和工具之间来回推进,而不是一次性把表达式算完:
最后的回答是:

这张图比单纯看命令行输出更直观。对我来说,重点已经不是算术结果本身,而是模型决策、工具执行、状态变化这些步骤都变成了一条可观察的轨迹。
第二个问题:None + 1
接着又遇到一个状态字段的问题:
问题出在这句:
原本以为 get 的第二个参数就是默认值,所以没传 llm_calls 时会用 0。这个理解只对了一半。
dict.get(key, default) 的默认值只在 key 不存在时生效。如果 key 存在,但值是 None,返回的仍然是 None。
也就是说,如果 Server 或 Studio 传进来的 state 是:
代码就会变成:
所以修复成:
这样字段缺失和字段为 null 都能按 0 处理。
顺手接入 LangSmith
今天也顺手把 LangSmith tracing 的环境变量理了一下。对 LangChain / LangGraph 项目来说,主要是:
配置好后,无论是脚本运行还是 Server 运行,都可以在 LangSmith 里看到 trace。
今天的收获
今天不是单独学某个语法点,更多是在把一个本地脚本慢慢推到可调试的 Server 形态。整个过程走下来,有几个点之前理解比较散,这次串起来了。
./main.py:agent 其实就是"从哪个文件里拿哪个变量",Python 不用像 JavaScript 那样手动 export,只要 agent 是顶层变量就能被拿到。
if __name__ == "__main__" 这次也顺手搞清楚了,它只在需要同时支持直接运行和被导入时才有用,服务化本身不强制加。
还有 langgraph-cli[inmem] 里的 [inmem] 就是 Python package 的 extra,dependencies: ["."] 就是告诉 Server 项目根目录在哪。
调试方面,Studio 适合看 graph 运行轨迹,test_agent.py 更像一个外部客户端验证整条链路通不通。
下一步看 thread、checkpoint、interrupt 和 human-in-the-loop,先把单个 graph 的本地 Server 跑明白,再扩展到多 Agent 编排。